360-degree feedback is a foundation for gaining well-rounded insights into employee performance. However, one aspect that often goes under the radar is the level of agreement within rater groups—how consistently peers, supervisors, or subordinates rate the same individual. While alignment among ratings is not always necessary, understanding these dynamics can significantly improve the interpretation of feedback and the success of development plans.
This blog will explore whether ratings within rater groups agree, why alignment might vary, and how organizations can use these insights to create more actionable feedback strategies.
360-degree feedback is a cornerstone for gaining well-rounded insights into employee performance. However, one aspect that often goes under the radar is the level of agreement within rater groups—how consistently peers, supervisors, or subordinates rate the same individual. Understanding these dynamics can significantly improve the interpretation of feedback and the success of development plans.
Key Insights on Within-Group Rater Agreement
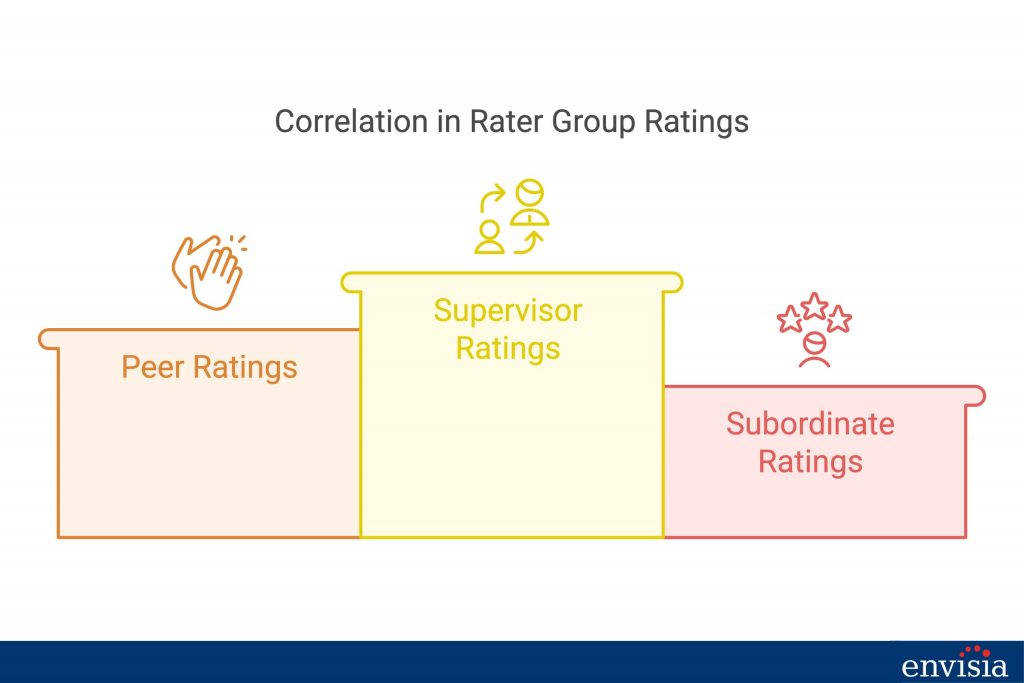
Research by Conway and Huffcutt (1997) demonstrates that variability in ratings within rater groups is a prevalent phenomenon. For instance, the correlation between ratings by two supervisors averaged 0.50, while peer ratings showed a correlation of 0.37, and subordinate ratings were even lower at 0.30. These figures underscore the complexity of aligning perspectives within groups.
What do these numbers reveal? The diverse experiences and priorities of raters within the same group shape their feedback, making perfect alignment unlikely. Instead of striving for uniformity, it’s essential to understand whether such alignment is beneficial and, more importantly, how to interpret these variations to guide meaningful action.

Factors Influencing Rater Discrepancies
Why do raters within the same group perceive performance differently? Several factors contribute to this phenomenon:
- Selective Focus: Raters naturally prioritize aspects of performance that resonate most with their roles and experiences.
- Observational Variance: Access to different contexts or opportunities to observe behavior can lead to discrepancies.
- Value Attribution: The weight raters assign to specific behaviors varies, reflecting individual or organizational priorities.
- Question Design: Ambiguities or inconsistencies in assessment questions can magnify differences in interpretation.
By recognizing these factors, organizations can assess whether alignment within groups is necessary and mitigate discrepancies to enhance feedback reliability.
Enhancing Rater Agreement Through Practical Strategies
To minimize discrepancies and ensure that 360-degree feedback remains a valuable tool for development, organizations can take the following steps:
- Design Better Questions: Craft questions that are clear, behaviorally specific, and directly relevant to the role in question. This reduces ambiguity and subjective interpretation.
- Implement Rater Training: Provide raters with guidelines and examples to standardize evaluation criteria. Training can help raters align their understanding of key behaviors and expectations.
- Encourage Reflective Feedback: Prompt raters to provide context for their ratings, explaining why they rated specific behaviors a certain way. This transparency can uncover useful insights and reduce misinterpretation.

Making the Most of Varied Feedback
When within-group ratings vary, the goal is not to smooth out differences but to leverage them effectively. Here’s how organizations can use discrepancies to their advantage:
- Identify Outliers: Statistical tools like standard deviation can highlight significant outliers, helping to pinpoint where perspectives diverge the most.
- Contextual Analysis: Discrepancies may reflect genuine differences in how behaviors are perceived in varied situations. For example, a peer may value teamwork more highly than a supervisor who prioritizes results.
- Integrate Varied Insights: Use these differences to create a holistic picture of the individual’s performance, identifying patterns that inform meaningful development plans.
Conclusion
The extent to which ratings within rater groups align provides valuable insights into differing perceptions of performance. While perfect alignment is rare, understanding the reasons behind variability can unlock deeper insights and more effective developmental outcomes. By refining assessment processes and thoughtfully evaluating alignment within rater groups, organizations can unlock the full potential of 360-degree feedback to drive targeted development.
Is your organization fully utilizing the potential of within-group agreement in 360-degree feedback? Explore tailored solutions with Envisia Learning to enhance your feedback processes and drive better developmental outcomes today.